




Received 12 December 2018; Revised 22 March 2019, 8 June 2019; Accepted 25 September 2019
This is an open access article under the CC BY license (https://creativecommons.org/licenses/by/4.0/legalcode)
Miroslava Nyulásziová (Muchová), Assistant Professor, Technical University of Košice, Faculty of Economics, Department of Applied Mathematics and Business Informatics, Němcovej 32, 040 01 Košice, Slovak Republic, e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it. 
Dana Paľová, Assistant Professor, Technical University of Košice, Faculty of Economics, Department of Applied Mathematics and Business Informatics, Němcovej 32, 040 01 Košice, Slovak Republic, e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Abstract
It is indisputable that the continuous development of digital technologies influences the business environment. Using information technologies means easier access to a huge amount of business information, which is hard to include in day-to-day decision-making. Traditional data processing methods in business management become inadequate. So, business process management approaches and business data analysis are the tools that could be utilized to optimize processes in a company and to harvest valuable information that can provide a variety of decision-making material for company management. This article deals with the analysis, modeling, and optimization of the transport process, as well as the design of a system for decision support in this process within a small transport company. The research is focused on the development of an innovative decision support system based on a company’s data analysis in order to improve the management of the transport service process.
Keywords: decision support, transport service process, data analysis, enterprise management
INTRODUCTION
Gartner (2018) defines Business Process Management (BPM) as “a discipline that uses various methods to discover, model, analyze, measure, improve, and optimize business processes.” The aim of BPM is to support the core objectives of the company. Davenport and Short (1990), define processes as a set of logical tasks or activities, which aim to achieve defined business goals. Implementing BPM principles into business management helps to analyze the current state of the company in total, or each department individually, and identifies areas for improvement within a company. Implementation of BPM is not a simple matter and it is as strongly influenced by the internal situation in a company as it is by the external factors (Gabryelczyk & Roztocki, 2018). The positive impact of introducing BPM technology is visible in improved productivity, cost savings, and flow-time reduction. The implementation of workflow management and straight-through processing methods results in automation throughout the core business processes of the company (Aalst, 2013). The new digital technologies enable and support growth and innovation in the new business environment (Vom Brocke & Mendling, 2018). At present, technologies influence the business strategy of the company itself and present a key to aligning IT investments with the business strategy. The objective of employing IT solutions into the business environment is to support work organization and the conjunction of the tasks needed to be done with the available company resources. To optimize the business process and its management, it is not enough to provide tasks and employees with smart tools, as it is important to analyze the connection amongst process activities within the process workflow, employees involved in the process, and data produced during the process lifecycle.
A rapid increase in digitalized data creates space for systematic business processes data collection. The extraction of these is a challenge because business informatics covers different kinds of information systems (ERP, CMS, SCM, etc.) with a huge amount of different data. One of them, with considerable potential, is logistics and its processes. Thanks to the significant development of information technologies (IT), optimized logistics presents a key factor in supporting the competitiveness of companies in the market. Logistics is the process-oriented activity of a company and presents a complicated system containing the number of goods and information flows, the amount of which grows at the management level (Chow, Choy, & Lee, 2007).
The main problem of logistics processes (including its transport service sub-process) in a company is the appropriate analysis of a huge amount of data (weather forecast, vehicle data, driver data, data about goods transported, etc.) created and collected from the different sources used during the process itself (Khabbazi, Hasan, & Sulaiman, 2013; Chung & Gray, 1999; Bardi, Raghunathan, & Bagchi, 1994; Lee & Park, 2008; Khabbazi, Ismail, Ismail, Mousavi, & Mirsanes, 2011). The main aim of the research presented in this paper is the introduction of the appropriate analytical methods that make it possible to improve the sub-process of drivers’ assignments on particular routes, in the case of a small Slovakian transport company. It presents one of sub-processes of the main process in the mentioned company. In addition, we describe the development of an automated system, which is able to download available data from the company’s vehicles and, using data mining models, provide up-to-date and accurate information for company management. Finally, we present the results obtained from the implementation of this system into the company’s environment. From a BPM point of view, the designed system allows one to get a more complex overview of the transporation process, especially about utilizing its resources (drivers, vehicles, fuel, etc.), which leads to a growth in the competitiveness of the company and more effective company management.
LITERATURE REVIEW AND RESEARCH BACKGROUND
At present, logistics, and particularly transportation services, are considered as an integral part of modern society. With logistics, it is important to consider the processes of planning, organizing and managing material flow, stockpiling, and the provision of services and related information from the place of origin to the point of consumption (Aalst, Adriansyah, Medeiros, & Arcieri, 2011; Ma, Xie, Huang, & Xiong, 2015). It should be stated that logistics is generally process-oriented. Analyzing and improving every process in a company could lead to a better performance of the company. Based on Dumas, Rosa, Mendling, and Reijers (2013) and Rosemann and Brocke (2015), Business Process Management (BPM) consists of six phases:
- Design – associated with the identification of current business processes. The result is a new or updated design process. In addition, at this stage, the tasks and responsibilities of the team members are defined, and the purpose of the process and the expected results are determined.
- Modeling – represents the possibilities of running processes in different scenarios. This is a what-if analysis. The aim is not only the processing of the modeling techniques but also the processing of the analytical methods.
- Implementation – related to the transformation of the models into executable processes. It includes two aspects - organizational change management and process automation. Model implementation includes, amongst other things, the creation of the process streams, data mapping, user interface creation, resource integration, and company systems usage, user, and role settings.
- Execution – this phase involves testing by users and, in the case of a functional process, deploying the process in companies. It also includes employee training or organizational changes related to the new processes.
- Monitoring – once the process has started, relevant data are collected and analyzed, process efficiency is measured, and progress is identified. The goal is to determine whether the process is successful in relation to the set goals.
- Optimization – a phase that includes methods to facilitate process development and enhancement. At this stage, mistakes or deviations and any changes needed to be implemented to make the process more efficient are recorded. However, the process is continuously improved according to the six mentioned phases.
Process analysis is a relatively young area that does not include only process of modeling, but it combines multiple disciplines (BPM, visualization, optimization, machine learning, data analysis, etc.) (Aalst et al., 2011). Combining multiple disciplines, it overcomes the limitations of the abstract processes. In addition, using process analysis is it possible to use new data to generate useful information within the business environment and to generate predictive and optimization models that may result in an improvement of business processes. From that point of view, process analysis combines the idea of modeling processes with data analysis methods, and the involvement of data mining methods means the deployment of information technology into business processes. Data mining itself is used only in those steps of the business processes where decisions are needed to be made (Chung & Gray, 1999).
At present, data analysis has increasing importance. Data analysis was mentioned for the first time at the beginning of the 1990s, together with the concept of data mining in databases. The first data analysis experiments began with data from databases filled with customer, product, and transaction information (Fayyad, 1996). From this viewpoint, we can understand data analysis as a process of selecting, exploring, modeling, and visualizing a large amount of data with the aim of discovering patterns or relationships that are not yet known. This way it is possible to get clear and more obvious results and use them to improve the process of analysis. The new technologies and data mining tools provide organizations with new insights from previously unused data sources (Terek, 2010).
Another article (Giraldo, Jiménez, & Tarabes, 2015) concluded that data mining, when applied to business data that supports processes, can improve business management as well as the achievement of enterprise objectives. The results of the case study mentioned in the article suggest that the integration of process management and data mining is a good choice for business (Giraldo et al., 2015). The authors of another article (Vukšić, Bach, & Popovič, 2013), pointed out the importance of linking BPM with enterprise information systems that result in better business performance. Aalst et al. (2011) were focused on extracting, processing, and analyzing data stored in BPM systems. The authors presented a methodology usable for extracting events, especially related to logistics company processes. Based on the data obtained and analyzed by data mining techniques, they showed that by using these methods, the shortcomings in the purchase order process could be identified. And finally, by analyzing and reconstructing partial processes, the logistics business process could be optimized, and the rules, overall knowledge, and the knowledge gained from data mining methods could be used by other business processes or for business management support, especially for decision-making. The author in the article (Feelders, Daniels, & Holsheimer, 2000) discussed the use of data mining in business processes, focusing on integrating models into the existing application systems of the enterprise. Because of this research, the author argued that it is important to use data mining methods to manage business processes.
Data mining technologies can help businesses collect and analyze various logistics management information in a timely and accurate manner. Data mining and related technologies can significantly help to improve the logistics decision-making process, to improve the quality of data analysis, to improve the quality of the service provided, to increase reliability, and so on (Daoping & Xiaojing, 2010). From previous facts it follows that data analysis and logistics are closely related. Logistics companies generate huge amounts of data that has the potential for new, further analyzes on a daily basis. The placement of various sensors on vehicles, inventory management, tracking of shipments, etc. - all these procedures allow one to generate a large amount of data (Berglund, Laarhoven, & Sharman, 2006). For logistics companies, it is difficult to extract valuable information from such a large amount of data to make timely and accurate decisions that are used to manage the business process and logistics itself; therefore, it is difficult to reduce logistics costs and increase enterprise revenues (Daoping & Xiaojing, 2010). Data itself and data analysis represent a source of inspiration for the logistics service providers to develop new business models, based on the analysis of the correlations between, for example, weather conditions, influenza epidemics and consumer internet purchases. This analysis can help to discover, for example, that bad weather leads to a higher realization of internet purchases, which means a higher number of packages sent (Paul & Saravanan, 2011). Such kinds of models can help to optimize processes and can result in an increase in customer satisfaction (Asef-Vaziri, Laporte, & Ortiz, 2007). At present, the optimization of logistics processes is the greatest opportunity to achieve cost savings, to improve decision-making, and to optimize inventory and mode of transport selection.
Recently, various research studies have highlighted the benefits of using data in the logistics process. Finding a good solution to the problem of vehicle and driver planning is extremely challenging due to complexity and different constraints (Peng, Li, & Yuanyuan, 2009). It is difficult to find the optimal solution leading to cost minimization (Golden, Raghavan, & Wasil, 2008; Boonprasurt & Nanthavanij, 2012). Goel and Irnich (2016) and Chen (2013) dealt with the problem of crew planning and their results demonstrated that effective crew planning could significantly reduce the operating costs of a company. The research of Laurent and Hao (2007) dealt with the problem of crew and vehicle planning in a limousine rental company. The objective was to find a way to maximize driver employment and optimize some of the economic objectives of the company in real-time and company resources management (e.g., scheduled drives could be canceled or modified at the last minute according to customer requirements). The main objective of the research done by Portugal, Lourenço, Paixão (2009) was to introduce new mathematical models explaining the complexity of crew planning and to present the easiness of the implementation of these models into real situations. The researchers introduced a generalized crew planning problem, where the user requirements are considered. Development of these models was based on the wide cooperation amongst different Portuguese bus transportation companies. The authors followed the operational research methodology steps (problem identification, system understanding, mathematical model formulation, model validation, best alternative selection, results presentation, implementation, and evaluation). The main goal was to find a model that can be integrated into the decision-making information system used for crew planning. The shortcoming of this research is that the authors do not consider drivers’ working time, EC Regulation No. 561/2006, and the problem of minimizing cost. Huisman and Wagelmans (2006) researched the problem of crew and vehicle planning using a dynamic solution based on the optimalization problem sequence. The authors in their research consider restrictions such as maximum working time, minimum break time, and so on. The suggested approach was tested on a small data set in one company and in a one-week planning horizon. The shortcoming of the described approach is the calculation time – it is too long to apply in practice and will not be easy to test in a practical environment, and for multiple warehouses, the dynamic approach does not work well.
The growing amount of data and its processing has become an important part of decision-making in logistics management. Data mining technologies are becoming more and more effective in modern logistics (Zhang & Zhang, 2015). Decision support models based on data acquisition overcome difficulties in analyzing business decisions. Modern logistics management depends on access to accurate and timely information (Langley, 1985). The structure of a modern logistics management system based on data mining is illustrated in the following Figure 1. The modern logistics management system consists of two main parts (Cogna & Huifeng, 2009; Liu & Guangsheng, 2008):
- data warehouse technology that allows one to store more historical data obtained from logistics activities as a database. It provides features to use historical data to predict and analyze trends and market sales. At the same time, data warehouse technology can describe and organize a vast array of diverse logistical management data that helps all members of the supply chain share logistics information;
- overall system design – because the knowledge base has been designed and implemented, decision-makers can easily select and use knowledge through a visual interface without a deeper understanding of the decision-making system, data warehouse, data mining, and other related activities.
Based on (Cogna & Huifeng, 2009), (Liu & Guangsheng, 2008), as shown in Figure 1, parts of the system and their features could be described by the following:
- logistics management decision support system – this system can provide logistics companies’ managers with the latest and most important knowledge that helps them to make the right and valid decisions (e.g., unified distribution of freight, driver load, vehicle load, motivation, and driver remuneration) (Strömberg & Karlsson, 2013);
- data mining module – according to the purpose of the logistics management decision (Lai, 2015) the algorithms for data mining (artificial neural networks, decision-making storms) (Laxhammar & Gascón-Vallbona, 2015), Naive Bayes classifier (Ferreira, Almeida, & Silvia, 2015; Muchová, Paralič, & Nemčík, 2017), clustering (Vogetseder, 2008)) are chosen and applied to the data in the database. This step extracts and cleanses useful information that is translated into a simplified form of the data.
- database and data warehouse – all business-related data are collected in databases and further organized, aggregated for on-line analysis into a data warehouse. Depending on the data mining characteristics and missions, the data needed for further analysis is selected (Huai, Shah, & Miller, 2005), (Ferreira et al., 2015);
- data collection and processing – the huge amount of data that is derived from logistics activities is collected, processed, transmitted and stored in the database in the format of the platform;
- user’s subsystem – users can access the system’s web interface through a corresponding protocol and send queries and requests to the system.
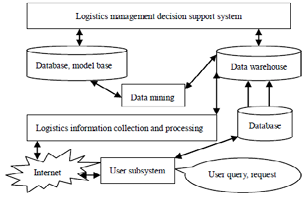
Figure 1. The structure of a modern logistics management information system
Source: Cogna & Huifeng (2009).
A decision support system (DSS) is an information system that supports business or organizational decision-making. It is a system that can analyze business data and present it in a form that makes it easier to make business decisions (Sauter, 2011; Moreno, Camacho, & Barrero, 2010). A properly designed decision support system is an interactive software system with goals like to identify and solve problems and make decisions. The decision support system has its substantiation even in logistics and its sub-processes. Moynihan, Raj, Sterling, and Nichols (1995) describe the design and development of a decision support system that uses heuristic simulation techniques to plan logistics and distribution activities and measure their impact on corporate profits. The proposed system was tested by industry experts. However, the system is not sufficient to quantify the costs and is insufficient to properly assess the impact of changes in the marketing and distribution environment. Hu and Sheng (2014) are concerned with the design of the decision support system for managing and optimizing public logistics information services for drivers, logistics customers, and relevant logistics and management service providers with the goal to minimize emissions. The basis of the proposed DSS is to provide real-time dynamic information with an aim to minimize logistics costs, energy, and pollution. The authors propose DSS as part of the management and optimization of logistics information services in China. Fanti (2015) deals with the design and development of a decision support system that can manage the flow of goods and business transactions between individual ports. DSS architecture is designed using simulation and optimization modules. The companies which want to use the proposed system must take tactical and operational decisions in logical systems. Simulation results show that the application of modern ICT-based solutions has enormous potential for efficient real-time traffic management, reducing delivery times in ports. The simulations also pointed out the possibility of reorganizing the workflow to exploit human resources more appropriately. DSS was also developed by Sperger and Mönch (2014), where the kernel of the system was based on a distributed hierarchical algorithm using company data stored in ERP. The system was used in the field of cooperative transportation planning. This system was also used to offer graphical user interfaces to interact with the users.
The integration of data mining into business processes is not a trivial task, even though BPMs provide flexible support for design, deployment, and business process management (Wegener & Rüping, 2010). Research, however, is still pointing to the limitations of literature on the effective use of BPM knowledge and data mining (Vukšić, Bach, & Popovič, 2013; Kang, Kim, & Kang, 2012). The integration of data mining into BPM is illustrated in the following Figure 2. It consists of three main components. One of them is process management. In this step, process management activities are defined. Another component, data processing, consists of collecting data from a data warehouse (for example using OLAP cubes). OLAP cubes are a multidimensional way to show the relationship between data. In the next step is it possible to apply data mining techniques through knowledge discovery. The obtained knowledge is used to update company business processes.
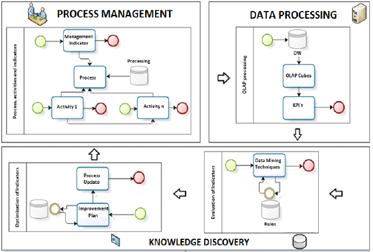
Figure 2. Integrating BPM and data mining
METHODOLOGY
Research motivation
In order to map the level of the automation transport processes amongst small Slovakian transport companies, a questionnaire survey was conducted in September 2016. Based on a predefined set of questions focused on fields like driving style analysis, use of information technology and way drivers are assigned to a planned delivery route, transport companies were asked to answer the questions and provide data that was later analyzed and interpreted.
By analyzing the responses from all the respondents, an attempt was made to verify whether the research proposed in this study would be interesting in practice as well. More than 300 logistics and transport companies were contacted.
One of the questions was focused on the practical usage of the system for proposing or deciding the assignment of drivers to routes by particular respondents. From the responses, about 10% of the respondents stated that they could not imagine using this system, 40% of the respondents would probably not use this system, while the other 50% would like to use such a system in their companies. In practice, drivers are assigned to specific routes by applying different principles. Figure 3 represents the distribution of the particular principles among respondents’companies.

Figure 3. Answers to the question obtained through the questionnaire survey
Another question was related to the way drivers are assigned to the planned delivery route, whether such assignment is based on using an automated system or if the assignment is manually based on some characteristics or features. According to the graphical summary of the responses in Figure 4, it can be seen that more than half of the companies assign their drivers to the delivery route manually, mostly according to the senders, recipients, weight, and size of the goods, size and load capacity of the vehicle. Companies also take into account the number of routes and, finally, compliance with transport legislation (adherence to rules for rest days). 17% of the companies surveyed stated that they do not assign drivers to a route according to any characteristics or preferences, and the same percentage of companies assign drivers to a route according to a predetermined location.

Figure 4. Answers to the question obtained through the questionnaire survey
From the results obtained in the questionnaire survey and the above-mentioned published studies results, the intention to design and create a decision support system for the process of assigning drivers to a route, as well as for analyzing other aspects of drivers’ routes, is more than justified. The results prove that logistic company managers do not have a comprehensive tool to facilitate their decision-making.
Case study: A transport logistics company
The whole research process was organized and implemented according to the typical model of research process used in the field of information systems (Oates, 2006). While solving the practical task in a small Slovak transport company, we have used several research methods and strategies at various phases of the research process. At the beginning of our research, a survey of published studies was realized to confirm the justness and practical usability of our research.
In order to evaluate the research done using data acquisition methods, we used a questionnaire and an observation of the current state of the company during the analysis phase and data analysis experiments. We also did an interview with a company manager responsible for the supported transport sub-process, to obtain answers about the initial situation in the transport company as well as about the user requirements for the decision support system that has been created. During the implementation of the methods mentioned above, we realized that the main objective of the research is to modify the transport sub-process in a way that provides an analysis of company data and recommendations for the company manager on the process of driver assignment to a particular route. At the same time, it is important to provide the results of the analysis in a suitable visual representation for faster and easier decision-making and company management.
The basis of the decision support system is the analysis of the relevant data. All available data analysis was performed using the CRISP-DM methodology. CRISP-DM is a methodology developed within the framework of the European Research Project. It represents the six life cycle stages of a data analysis project, which constitutes a universal methodology applicable in different areas (Pour, Maryška, & Novotný, 2012). There are close relationships between the different stages of the life cycle of the project to help organizations understand the data mining process. The following Figure 5 shows the process model CRISP-DM (Paralič, 2003).
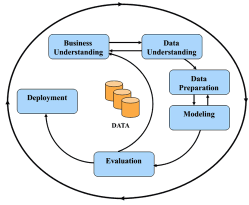
Figure 5. Phases of the CRISP-DM reference model
Figure 5 shows a data analysis cycle based on CRISP-DM and, as mentioned, consists of six phases (Fayyad, 2015):
- Business understanding – the first phase is about defining business goals and requirements from a managerial perspective as well as defining data mining goals and a preliminary project plan.
- Data understanding – the phase starts with the initial data collection, which aims to get the necessary and relevant data from existing databases, load and integrate them. Initial data collection also includes a description of the methods used to retrieve data. The analyst’s task is to identify potential problems and find solutions.
- Data preparation – after getting acquainted with the data, the next step is to prepare the data. The data preparation phase covers all the activities associated with creating the final set of data to be used for modeling. Tasks associated with data preparation can be performed multiple times in any order. These are tasks such as data collection, data cleaning, data construction, data integration, and data formatting.
- Modeling – this is the process of applying data mining methods with setting parameters to optimal values. Modeling consists of four tasks: selecting modeling techniques, testing the proposal, building a model, and evaluating the resulting models. The first step in modeling is the choice of the modeling technique to be used. It can be, for example, decision trees, association rules, neural networks, and so on.
- Evaluation – the previous steps of the review addressed factors such as the accuracy and the generality of the model. At this stage, an assessment is made of the extent to which the model meets business objectives and whether there is any business reason why this model is inadequate. Another option, if time and budget constraints allow, is to test the models. The review process is trying to find out if there is a task that has been overlooked in some way, or if something has not got lost. It’s about controlling the whole process. This check also includes questions about quality assurance, such as whether the model has been created correctly, whether the correct attributes have been used, and so on. Depending on the results of the process evaluation, the reviewers decide how to proceed further. This will determine whether to complete the project and go to the next stage – deploy or initiate further iteration or create a new data mining project.
- Deployment – the deployment phase takes into account the results of the evaluation and determines the deployment strategy. An important role at this stage is the monitoring and maintenance of the plan if the project and the results themselves form part of everyday business. A carefully prepared monitoring and maintenance plan helps prevent misuse of the data acquisition and the results of the analysis using created models. The detailed monitoring plan takes into account the specific type of deployment. At the end of the project, the project team will evaluate the positives, the negatives, determine what needs to be improved, and prepare the final report. Depending on the deployment plan, this report may only be a project summary, or it may be a final version, including a comprehensive presentation of the results.
After the development of DSS and its implementation in a transport company environment, experiments using data analysis with the real company data were done. The results achieved by the performed experiments were evaluated taking into account the CRISP-DM methodology, and quantitative analysis methods were used to evaluate the obtained data (Kurgan & Musilek, 2006; Waller & Fawcett, 2013). In order to evaluate the data obtained from the interview with the transport company manager, qualitative data analysis was used (Šuc & Bratko, 2001; Šuc & Bratko, 2003).
The problem definition and the solution design
Within the business understanding phase, we focused on modifying an existing process and information analysis appropriate to the transport company manager in order to help him obtain the necessary and valuable information from the company systems. Thanks to such information, the user can monitor not only vehicle, driver, or fleet consumption but can also monitor other factors that influence fuel consumption and make timely and accurate decisions. The analyzed company operates a road freight transport business, shipping goods to the final consumer or other businesses. The Dynafleet Online system – Volvo Truck Corporation – is used to manage the transport processes. The company also uses a second system to communicate with vehicles. The communication between the system and the vehicles is via the mobile telephone network. The vehicles are set to regularly export data to the system, or the dispatcher can manually download data. Information downloaded from the vehicles is stored in the database. Subsequently, it is possible to export the data to an Excel file for further analysis. Prior to implementing the innovative decision tool, the only data provided by the system was about the vehicle’s location and event data for the vehicle or group of vehicles over a certain period of time (event time, driver’s name, distance traveled, fuel, fuel status, location, weight, etc.) and the data that provided information about the driving style of the driver (average speed, top gear, economy, cruise control, idling, etc.).
After comparing the interview results and the current system functions analysis, it can be stated that the current system used by the transport company is inadequate. It is possible to choose different reports for analysis (e.g., Overview report, Summary report, Exception report, Fuel and adBlue report, Mileage report, Time report for the vehicles and drivers), but there is no possibility to choose more interesting attributes for the manager. In the tool used currently, it is not possible to create customized reports and charts and compare consumption and other various attributes (e.g. above economy time, top gear, engine load, overspeed, cruise control, etc.), facts that would interest company management. Based on the requirements defined by the company manager, Dynafleet Online – Volvo Truck Corporation software cannot combine attributes and results can only be viewed according to predefined attributes tools (Figure 6).
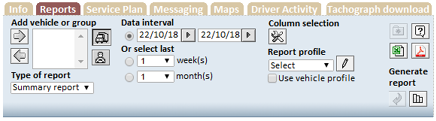
Figure 6. The current data representation system
Source: Dynafleet Online – Volvo Truck Corporation.
In addition, the data collected and stored in this system’s database is automatically deleted after a certain time, so it is not possible to work with historical data. Figure 7 represents the analyzed process without the proposed decision support system, while Figure 8 shows the same process but with DSS implemented. In the case of Figure 7, the manager manually downloads data generated and collected by the Dynafleet tool and decides which driver to assign to a route based on the obtained reports. This process is quite time consuming because the manager must manually collect the data needed for the decision.
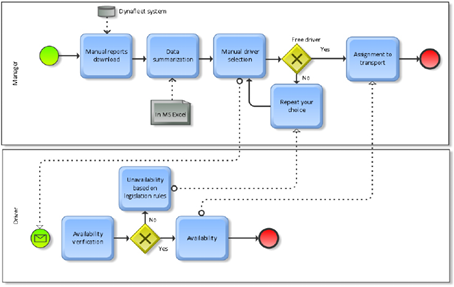
Figure 7. Processes before the introduction of the DSS system
Source: own processing – ARIS Express.
In the next picture, the automated process of assigning drivers to a route using the proposed system is presented. The system works on a common database that allows more comfortable querying and statistical analysis. The success of the proposed system is that it saves time, creates flexibility, and improves decision-making based on up-to-date data. The objective of the system set by the management is to increase the company’s profits through more efficient driver assignments, as well as increased fleet management and driver analysis. As stated in Igbaria, Sprague, Basnet, and Foulds (1996), DSS does not replace the decision-maker, but it supports the decisions where the part of the analysis can be systematized by the computer so that the decision-maker’s insight and judgment are improved. The system proposes decision-making advice, which is more comfortable for the company manager. Based on the process and data collected by company analysis, it was found that not all the data stored in the database were needed for business management and transport management processes. In order to optimize the transport management process, it was necessary to pre-process the data. The preparation of the data consisted of the selection of suitable attributes and the removal of irrelevant attributes. We removed the attributes that contained the same amount of value from the data that provided the fuel consumption information. Further, we removed from the driving style information the data attributes that were not needed for analysis. We removed other attributes due to redundant information in the system. Finally, the innovated system uses information from the existing enterprise database and implements a unified analytical approach in order to make the relationships between data and used algorithms more visible.
The analysis of the current situation and functions provided by the Dynafleet Online system led us to design an innovative support system based on data analysis and visualization. The main idea of the system is covered by the integration of the data mining methods into BPM (as is shown in Figure 2). The main objective of the designed transport system based on user requirements is to analyze the driving style of individual drivers and the vehicles of the transport company. It has to be a software system, which makes it possible to update the vehicle data daily and provide it in a suitable visual presentation. Based on the models of Congna and Huifeng (2009) and according to Liu and Guangsheng (2008), we propose our own model of the innovated transport DSS, which supports the process of the transport realized by company (see Figure 9). Unlike this mentioned system (described in Figure 1), our DSS’s main structure does not cover the modern logistic management information system as a whole, but only the concerns on transport services carried out by the analyzed company.
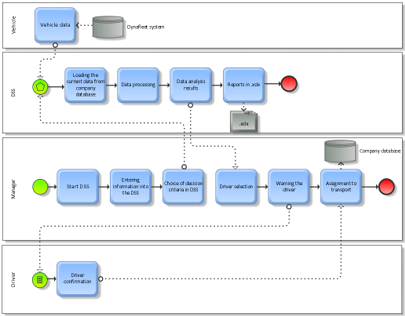
Figure 8. Processes after the introduction of the DSS system
Source: own processing – ARIS Express.
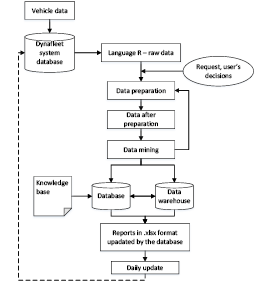
Figure 9. Structure of the proposed logistics DSS
Parts of the designed DSS can be briefly described as following:
- vehicle data – presents each vehicle’s data collected by a built-in mobile unit about the traffic and status of the vehicle in the current situation;
- dynafleet database – means a data repository, where data is automatically stored in the database via a vehicle mobile unit;
- language R – raw data using R language, data from the Dynafleet database is automatically downloaded for the following data processing;
- data pre-processing – includes basic pre-processing tasks such as data clearing (deleting or filling in missing values, removing inconsistent values), removing redundant and duplicated data, transforming, data reduction (attribute selection). Additionally, data pre-processing includes the generation of the new attributes, the integration (merging) of two data files;
- data after preparation – contains already pre-processed data set ready for further data modeling;
- data mining tools – applying Machine Learning Algorithms (such as Naive Bayes Classifier, and Decision Tree; Fayyad, 1996; Kantardzic, 2003; Perrey, Spillecke, & Umblijs, 2010);
- database – all the data is stored in the database, along with an understanding of the knowledge base. The data is later organized and aggregated for on-line analysis into a data warehouse;
- data warehouse – the historical data is stored here and, according to the purpose of the decision-making, it is available to users to create different analyzes and charts;
- knowledge base – provides information about working hours, rest days and days off. The data is kept up to date;
- reports are created in MS Excel, in .xslx format – OLAP analytics information is aggregated into an Excel spreadsheet, where the data analysis tools for creating a contingent table provide the user with various reports, whether in the form of spreadsheets or graphs.
Compared to the existing transport management systems described in Congna and Huifeng (2009) and Dejun and Huifeng (2008), the proposed system is, in addition, complemented by a daily data update, when every day (“fresh”) data from the system database is reloaded into the R program pre-processed to the data mining models required form. The data mining models are re-trained every day after new data is imported. By deploying a system that improves the driver assignment process to the route, we expect a 10% reduction (as was presented in the study by Ferreira et al., 2015) in daily fuel consumption, resulting in a reduction in diesel costs of more than 20 € per vehicle per day. It means savings of more than 6000 € per vehicle per year for the company.
RESULTS
Practical implementation of DSS and acquired results
The proposed system and its practical applicability were tested in the environment of a Slovak transport company. However, before the implementation itself of the newly-developed decision system, the company’s processes and technologies were analyzed in order to secure the customization of the proposed system according to the needs of the analyzed company.
According to Oates (2006), designing and creating an IT artifact focuses especially on creating new IT products. In our case, it is a new decision support system. The proposed system provides the transport company manager with a better understanding of activity and data processing, which supports decision-making on driver and vehicle assignment to routes. The system design was executed using Microsoft SQL Server 2016, Visual Studio, and MS Excel with the Data Analysis tool. An important task was to divide the data into a table of facts and dimension tables on the basis of already prepared data. The database data model was created in MS SQL Server 2016, where 9-dimension tables and one table of facts were created.
The created analysis, implemented in the tracing application, is simple and easy to interpret and understand. Through various filters, users can see and search/analyze data from different angles without any limitations. Reports can help to track fuel consumption of individual vehicles or drivers, as well as find reasons for higher fuel consumption. Compared to the possibilities of the currently used analytics, the obtained results are something new, as the existing solutions do not use Business Intelligence approaches to visualize data.
The system was designed for a transport company manager to better understand and process the data, in order to support decisions when assigning drivers and vehicles to a route. Through the graphical interface, the user can update the data from the previous day, and the data can be evaluated statistically and graphically. In addition, the system always offers an up-to-date overview of the factors affecting fuel consumption and overall rating. The system can also recommend a driver for the planned route based on the specified parameters. After updating the data and saving it to the database, the company manager can download data in the form of a pivot table and generate the required reports.
For easier operation of the proposed system, the graphical interface of DSS is divided as follows:
- data update – data retrieval, data preparation, data updating and sending data to MS Excel with the possibility of visualization;
- statistics – includes descriptive characteristics of the final, daily updated file, including graphs and correlations;
- impact on average fuel consumption – machine learning algorithms run in the background of the application. The objective is to analyze the impact of the attributes on average fuel consumption;
- impact on the overall rating – in this case, the machine learning algorithms run in the background to analyze the impact of attributes on the overall rating;
- decision tree – the results of decision tree analysis can provide support for transport decisions;
- recommendation – driver recommendation for the planned delivery route. This is also a fully automated and updated functionality.
Figure 10 shows a part of the user interface of the system, the menu for selecting the parameters, based on which the system calculates the probabilities of the individual drivers. The user chooses the driver’s starting position along with the route’s destination. Next, it chooses the distance between these two locations. Likewise, the user chooses the weight of the load. The month is included in the model as the results of the analysis have shown that the month influences average fuel consumption and affects the driving style of the drivers. As a decision attribute, we chose average fuel consumption divided by three intervals. In the background of the application, the models for all drivers are triggered, the inputs to the test set are user-defined parameters, and the output is the probability of the average fuel consumption (or overall rating) of the individual drivers.
Figure 11 shows the output of the specified parameters and shows the probability of achieving fuel consumption in three classes for individual drivers. After the user has defined the route, the program displays the probability of reaching a certain fuel consumption class on the route. These probabilities are calculated using the Naive Bayes classifier. In machine learning, the Naive Bayes classifier is a simple probabilistic classifier. It is based on probability models, and their role is to predict whether the example belongs to a certain class, based on the Bayesian condition of probability (Rish, 2001).
The table will help the manager decide which driver to assign to a route, in order to achieve the lowest possible fuel consumption. For a better understanding of the practical situation: The manager could choose Driver_B because, with a probability of 57%, he is likely to consume less than 26.5 l / 100 km. Driver_D on the same route, with a probability of 98%, will likely consume more than 31.63 l / 100 km.
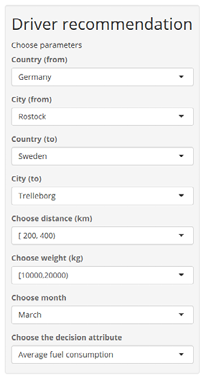
Figure 10. Selecting the parameters for a driver recommendation
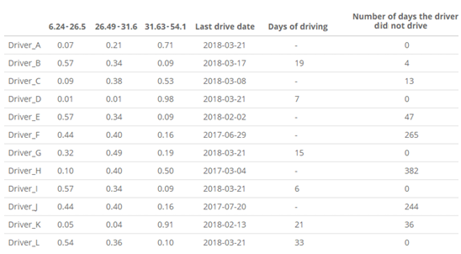
Figure 11. Probability of fuel consumption at three intervals
Because our transport management proposal also consists of the knowledge base, the rules stored in the system based on the logistics management structure are used in this part of the application. The last three columns of the table, shown in Figure 11, provide data about the time spent driving by each driver. The data in these columns are linked to March 21, 2018, when the proposed application was tested in the transport company. Information and data are updated from the previous day, which is in our case is March 20, 2018. The column “Last driving date” indicates the date when the driver last drove. Since the company has six vehicles, the number of driving days is calculated from the date in the last row of the individual vehicles, with the condition of the attribute – driver’s name being tested. This information is entered into a table for the particular driver. The number of days the driver missed uses the current date function and counts from the last driving date. The number of driving days will help the manager of the company decide whether the driver is already entitled to a rest day. The information on the number of days the driver missed gives information about the driver’s free time.
The results of the experiments showed that choosing a driver and correctly applying driving style recommendations could have a significant impact on the reduction of fuel consumption. The acquired knowledge from the models should, therefore, be useful for managers who are in charge of assigning a driver to a route. Based on all the information about the company and our system structure, we expect that, after proper implementation of the project, the average fuel consumption per vehicle could reduce by 10% per day. It means a 20 € reduction in diesel per day per vehicle and a yearly saving in the level of 6000 € per vehicle.
The pilot test of the system within the transport company environment took place on March 21, 2018, and the system is currently still in a prototype testing phase. However, the company manager can look and compare the first results, as fuel consumption is available before deployment of the system into the test operation. In Table 1, we can see the average fuel consumption and the average rating of the driver’s driving style before deployment of the system and the results during system testing. The average consumption of all the drivers before deployment was 31.109 l/100 km. This consumption is from 2 June 2015 to 21 March 2018. During the test, when the company manager used the functions of the system and assigned the driver to the planned delivery route as recommended by the system, the average fuel consumption decreased by 1.9 l/100 km. System test data were collected for March-October 2018. In the table, we can see the fuel consumption of individual drivers. We see a significant improvement has been achieved by the Driver_A, when average fuel consumption fell by 3.69 l/100 km.
|
Before deploying the system |
System in testing |
|||
|
Average fuel consumption (l/100km) |
Average rating (%) |
Average fuel consumption (l/100km) |
Average rating (%) |
|
|
Driver A |
32.95 |
74.98 |
29.26 |
77.65 |
|
Driver B |
30.93 |
76.86 |
28.20 |
77.35 |
|
Driver C |
30.81 |
73.63 |
28.57 |
78.26 |
|
Driver D |
31.93 |
76.86 |
29.44 |
78.45 |
|
Driver E |
29.96 |
77 |
28.98 |
77.56 |
|
Driver F |
31.86 |
77.2 |
29.19 |
78.61 |
|
Driver G |
32.30 |
74.85 |
32.17 |
76.12 |
|
Driver H |
30.89 |
77.38 |
29.18 |
78.23 |
|
Driver I |
29.96 |
76.99 |
30.40 |
75.12 |
|
Driver J |
30.94 |
75.5 |
28.64 |
79.26 |
|
Driver K |
31.91 |
75.51 |
29.15 |
77.23 |
|
Driver L |
30.87 |
76.58 |
29.16 |
77.87 |
Further improvement was achieved by the B, C, D, F, J, and K drivers, where average fuel consumption decreased by more than 2 l/100 km. Conversely, Driver_I got worse and Driver_G achieved approximately the same fuel consumption. Total average fuel consumption declined by 6.12%. Despite the short period of testing of the system, we can say that if the manager applies the system to real-life operations, it can save both fuel and finance. In addition to the average consumption, we can see an improvement in the overall rating in the table. The overall rating is the driver’s driving style, which is affected by a number of other attributes such as cruise control, average speed, overall distance, braking, economy driving, and more. This gives the manager a quick overview of how the driver was driving the route. Based on the results in the table, we can say that drivers’ rating has improved by about 4%.
DISCUSSION AND FUTURE RESEARCH
The system the company is currently using makes it possible to create only simple analyzes and preview the results based on predefined attributes. Compared to the original system, the newly developed decision supporting system provides managers with data about fuel consumption and factors influencing this consumption. Besides this basic information, it also provides functionality for monitoring individual drivers (driving style and consumption, vehicle types, number of journeys, etc.) and saving real data to a database already containing all historical data. In addition, although it was not the purpose of our research, it is possible to monitor the vehicle occupancy as well as the overall distance driven by individual drivers. Data analysis results are visualized in the form of reports and charts. In this way, they are helpful to the company manager who can use them for motivating and evaluating employees, whilst providing drivers with recommendations on how to reduce fuel consumption. Besides everything mentioned, the developed system helps to support the decision-making process of the selected business processes of the transport company.
The effort to maintain the competitiveness of the company is a driving force behind the introduction and constant innovation of business informatics. Effective management, based on the data provided by the company’s different information systems, is a necessity at present. And, as was presented in the paper and in other research papers (Bardi et al., 1994; Rish, 2001; Pighin, 2016), data analysis and process management are vital in the modern logistics environment. The main objective of the paper was to present the design of the decision support system. The system is based on the principle of the implementation of data mining to support the decision process of driver assignment/selection within a small transport company. The research of studies focused on the same problem had shown that a good level of system automation within small companies results in employing ERP (Enterprise Resource Planning) systems that are focused on integrating various business processes. The shortage is that these systems are not developed to support all the specialties of the logistic process itself. The proposed system is based on transport management’s sub-process analysis. The developed system links the data mining area to the decision-making process in the mentioned process. The capability to upgrade the data has shifted the system to a higher level because the system is capable of training application-based models, and the company manager can be provided with up-to-date information. We can state that after testing the system in a logistics company for about 8 months, the company has reduced its fuel consumption by 6.12% and its managers have used the data in different areas of decision-making, and rewarding and motivating employees. Such a proposed system can be implemented in all logistics companies using Volvo vehicles and the Dynafleet Online system. For other companies, it would be necessary to adjust the system settings so that they track the specific attributes set by their information systems.
It is possible to extend the scope of the presented decision support system by introducing other attributes to the data analysis models (e.g., weather-enhanced data model, current traffic situation, etc.).
CONCLUSION
As stated by Swenson and Rosing (2015), it is important to realize that BPM is not just about the automation of business processes, but about improving them and also its improvement cannot be secured by the implementation of the new information system or application. But as is stated above “Business process management (BPM) is a discipline involving any combination of modeling, automation, execution, control, measurement, and optimization of the business activity flows in applicable combination to support enterprise goals, spanning organizational and system boundaries, and involving employees, customers, and partners within and beyond the enterprise boundaries.” From that follows, that automation of the process is an important part of BPM. Applying a BPM approach depends on the needs and the possibilities of every particular business. The research concerned one of the processes of a small transport company, the transport services and the possibility to implement a decision support system to its environment. The transport company identified the transport process as its core process and the management of the company was interested in the analysis of this process. Besides the presented questionnaire results, the interest of the company’s management was the reason and motivation as to why we were not concerned about implementing the BPM approach to all processes but, instead, started by analyzing and automating this company’s sub-process. It presents the first approach to business processes improvement, including a more precise analysis of the company as a whole.
The use of data mining methods and techniques in business processes is increasing, but the corresponding level of utilization has still not been achieved. The reviewed literature demonstrates that data mining in business process management is mainly used to support decision-making. However, it should be noted that there is not much research going on in the implementation of data mining in business processes and thus creates a place for further research and the practical implementation of developed automated systems in business management.
References
Aalst, W. M. P. (2013). Business process management: A comprehensive survey. Retrieved from http://downloads.hindawi.com/journals/isrn.software.engineering/2013/507984.pdf https://doi.org/10.1155/2013/507984.
Aalst, W. M. P., Adriansyah, A., Medeiros, A. K. A., & Arcieri, F. (2011). Process mining manifesto. Retrieved from https://link.springer.com/content/pdf/10.1007/978-3-642-28108-2_19.pdf
Asef-Vaziri, A., Laporte, G., & Ortiz, R. (2007). Exact and heuristic procedures for the material handling circular flow path design problem. European Journal of Operational Research, 176(2), 707-726. http://dx.doi.org/10.1016/j.ejor.2005.08.023
Bardi, E. J., Raghunathan T. S., & Bagchi P. K. (1994). Logistics information systems: The strategic role of top management. Journal of Business Logistics, 15(1), 71-85.
Berglund, M., Laarhoven, P., & Sharman, G. (2006). Third-party logistics: Is there a future. International Journal of Logistics Management, 59-70. http://dx.doi.org/10.5923/j.logistics.20140301.03
Boonprasurt, P., & Nanthavanij, S. (2012). Optimal fleet size, delivery routes, and workforce assignments for the vehicle routing problem with manual materials handling. International Journal of Industrial Engineering: Theory, Applications and Practice, 19(6), 252-263.
Congna, Q., & Huifeng, Z. (2009). Study on application of data mining technology to modern logistics management decision. International Forum on Information technology and Applications (pp. 433-436). http://dx.doi.org/10.1109/IFITA.2009.93
Daoping, W., & Xiaojing, X. (2010). Analysis and design of the logistics information system based on data mining. Intelligent computation Technology and Automation (pp. 635-638). http://dx.doi.org/10.1109/ICICTA.2010.133
Davenport, T. H., & Short J. E. (1990). The new industrial engineering: Information technology and business process redesign. Sloan Management Review, 31(4), 11-27.
Dumas, M., Rosa, M., Mendling, J., & Reijers, H. A. (2013). Introduction to business process management. Fundamentals of Business Process Management, 5(4), 1-31. http://dx.doi.org/10.1007/978-3-642-33143-5_1
Fanti, M. P. (2015). A simulation based decision support system for logistics management. Journal of Computational Science, 10, 86-96. http://dx.doi.org/10.1016/j.jocs.2014.10.003
Fayyad, U.M. (1996). Advances in Knowledge Discovery and Data Mining. Cambridge MA: AAAI Press/MIT Press.
Feelders, A., Daniels, H., & Holsheimer, M. (2000). Methodological and practical aspects of data mining. Information & Management, 37(5), 271-281. http://dx.doi.org/10.1016/S0378-7206(99)00051-8
Ferreira, J., Almeida, J., & Silvia, A. (2015). The impact of driving styles on fuel consumption: A data warehouse and data mining based discovery process. Transactions on Intelligent Transportation Systems, 16(5), 2653-2662. http://dx.doi.org/10.1109/TITS.2015.2414663
Gabryelczyk, R., & Roztocki, N. (2018). Business process management success framework for transition economies. Information Systems Management, 35(3), 234-253. http://dx.doi.org/10.1080/10580530.2018.1477299
Gartner (2018). Business Process Management (BPM). Retrieved from https://www.gartner.com/it-glossary/business-process-management-bpm
Giraldo, J., Jiménez, J., & Tabares, M. (2015). Integrating business process management and data mining for organizational decision making. Research in Computing Science, 100, 89-102.
Goel, A., & Irnich, S. (2016). An exact method for vehicle routing and truck driver scheduling problems. Transportation Science, 51(2), 1-18. http://dx.doi.org/10.1287/trsc.2016.0678
Golden, B., Raghavan, S., & Wasil, E. (2008). The vehicle routing problem: Latest advances and new challenges. Operations Research/Computer Science Interfaces Series. Retrieved from https://www.springer.com/series/6375
Hu, Z. H., & Sheng Z. H. (2014). A decision support system for public logistics information service management and optimization. Decision Support Systems, 59, 219-229. http://dx.doi.org/10.1016/j.dss.2013.12.001
Huai, T., Shah. S. D., & Miller, J. W. (2006). Analysis of heavy-duty diesel truck activity and emissions data. Atmospheric Environment, 40, 2333-2344. http://dx.doi.org/10.1016/j.atmosenv.2005.12.006
Huisman, D., & Wagelmans, A. (2006). A solution approach for dynamic vehicle and crew scheduling. European Journal of Operational Research, 172(2), 453-471. http://dx.doi.org/10.1016/j.ejor.2004.10.009
Chen, S. (2013). A crew scheduling with Chinese meal break rules. Journal of Transportation Systems Engineering and Information Technology, 13(2), 90-95. http://dx.doi.org/10.1016/S1570-6672(13)60105-1
Chow, H.K.H., Choy, K. L., & Lee W. B. (2007). A dynamic logistics process knowledge-based system - An RFID multi-agent approach. Knowledge Based Systems, 20(4), 357-372. https://doi.org/10.1016/j.knosys.2006.08.004
Chung, H. M., & Gray, P. (1999). Special section: Data mining. Journal of Management Information Systems, 16(1), 11-16. http://dx.doi.org/10.1080/07421222.1999.11518231
Igbaria, M., Sprague, R., Basnet, C., & Foulds, L. (1996). The impact and benefits of a DSS: The case of Fleetmanager. Information and Management, 31(1996), 215-225. http://dx.doi.org/10.1016/S0378-7206(96)01078-6
Kang, B., Kim, D., & Kang, S. H. (2012). Periodic performance prediction for real-time business process monitoring. Industrial Management and Data Systems, 112, 4-23. http://dx.doi.org/10.1108/02635571211193617
Kantardzic, M. (2011). Data mining, concepts, models, methods, and algorithms, 2nd edition, London: Wiley-IEEE Press.
Khabbazi, M. R., Hasan, M. K., & Sulaiman, R. (2013). Business process modelling in production logistics: Complementary use of BPMN and UML. Middle East Journal of Scientific Research, 15(4), 516-529. http://dx.doi.org/10.5829/idosi.mejsr.2013.15.4.2280
Khabbazi, M. R., Ismail, M. Y., Ismail, N., Mousavi, S. A., & Mirsanes, H. S. (2011). Lotbase traceability requirements and functionality evaluation for small to medium-sized enterprises. International Journal of Production Research, 49(3), 731-746. http://dx.doi.org/10.1080/00207540903530810
Kurgan, L., & Musilek, P. (2006). A survey of knowledge discovery and data mining process models. The Knowledge Engineering Review, 21(1), 1-24. http://dx.doi.org/10.1017/S0269888906000737
Lai, W.T. (2015). The effects of eco-driving motivation, knowledge and reward intervention on fuel efficiency. Transportation Research Part D: Transport and Environment, 34, 155-160. http://dx.doi.org/10.1016/j.trd.2014.10.003
Langley Jr., C. J. (1985). Information-based decision making in logistics management. International Journal of Physical Distribution & Materials Management, 15(7), 41-55. http://dx.doi.org/10.1108/eb014623
Laurent, B., & Hao, J. (2007). Simultaneous vehicle and drivers scheduling: A case study in a limousine rental company. Computers & Industrial Engineering, 53(3), 542-558. http://dx.doi.org/10.1016/j.cie.2007.05.011
Laxhammar, R., & Gascón-Vallbona, A. (2015). Vehicle models for fuel consumption. EC FP6 project COMPANION deliverable D4.3. Retrieved from https://pdfs.semanticscholar.org/b350/cff0d479e4bec2de86502c8d12a639e1497c.pdf
Lee, D., & Park, J. (2008). RFID-based traceability in the supply chain. Industrial Management and Data Systems, 108(6), 713-725 http://dx.doi.org/10.1108/02635570810883978
Liu, D., & Guangsheng, Z. (2008). Application of data mining technology in modern agricultural logistics management decision. Retrieved from http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.456.747&rep=rep1&type=pdf
Ma, H., Xie, H., Huang, D., & Xiong, S. (2015). Effects of driving style on the fuel consumption of city buses under different road conditions and vehicle masses. Transportation Research Part D: Transport and Environment, 41, 205-216. http://dx.doi.org/10.1016/j.trd.2015.10.003
Moreno, M. D. R., Camacho, D., & Barrero D. F. (2010). A decision support system for logistics operations. In Soft Computing Models in Industrial and Environmental Applications (pp. 103-110). Berlin: Springer. http://dx.doi.org/10.1007/978-3-642-13161-5_14
Moynihan, G. P., Raj P. S., Sterling, J. U., & Nichols, W. G. (1995). Decision support system for strategic logistics planning. Computer in Industry, 26(1), 75-84. http://dx.doi.org/10.1016/0166-3615(95)80007-7
Muchová, M., Paralič, J., & Nemčík, M. (2017). Using predictive data mining models for data analysis in a logistics company. Information Systems Architecture and Technology, 26, 161-170. http://dx.doi.org/10.1007/978-3-319-67220-5_15
Oates, B. J. (2006). Researching Information Systems and Computing. London: Sage Publications.
Paul, A., & Saravanan, V. (2011). Data mining analytics to minimize logistics cost. International Journal of Advances in Science and Technology, 2(3), 433-436.
Peng, W., Li., M., & Yuanyuan, X. (2009). Research on logistics oriented spatial data mining techniques. In 2009 International Conference on Management and Service Science. Retrieved from https://ieeexplore.ieee.org/abstract/document/5302896 http://dx.doi.org/ 10.1109/ICMSS.2009.5302896
Perrey, J., Spillecke, D., & Umblijs, A. (2013). Smart analytics: How marketing driver short-term and long-term growth. In D. Court, J. Perrey, T. McGuire, T. Gordon, & D. Spillecke (Eds.), Big Data, Analytics, and the Future of Marketing & Sales (pp. 1-40). New York: McKinsey & Company.
Pighin, M. (2016). Logistic and production computer systems in small-medium enterprises. In 2016 39th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO) (pp. 1168-1172). IEEE: Opatija, Croatia. http://dx.doi.org/10.1109/MIPRO.2016.7522316
Portugal, R., Lourenço, H.R., & Paixão, J.P. (2009). Driver scheduling problem modelling. Public Transport, 1(2), 103-120. http://dx.doi.org/10.1007/s12469-008-0007-0
Pour, J., Maryška, M., & Novotný, O. (2012). Business intelligence v podnikové praxi. Professional Publishing, 276 (in Czech).
Rish, I. (2001). An empirical study of the naive bayes classifier. Technical report, IBM Research Division. Retrieved from https://www.cc.gatech.edu/~isbell/reading/papers/Rish.pdf
Rosemann, M., & Brocke, J. (2015). The six core elements of business process management. In International Handbook on Information Systems (pp. 105-122) Berlin, Cham: Springer. http://dx.doi.org/10.1007/978-3-642-45100-3_5
Sauter, V. L. (2011). Decision Support Systems for Business Intelligence. London: Wiley.
Strömberg, H.K., & Karlsson, I.C.M. (2013). Comparative effects of eco-driving initiatives aimed at urban bus drivers - results from a field trial. Transportation Research Part D: Transport and Environment, 22, 28-33. http://dx.doi.org/10.1016/j.trd.2013.02.011
Swenson, K. D., & Mark von Rosing. (2015). The Complete Business Process Handbook. Waltham, USA: Morgan Kaufmann. http://dx.doi.org/10.1016/B978-0-12-799959-3.00004-5
Sprenger, R. & Mönch, L. (2014). A decision support system for cooperative transportation planning: Design, implementation and performance assessment. Expert Systems with Applications, 41(2014), 5125-5138. http://dx.doi.org/10.1016/j.eswa.2014.02.032
Šuc, D., & Bratko, I. (2001). Induction of qualitative trees.
Šuc, D., & Bratko, I. (2003). Qualitative reverse engineering. Retrieved from https://www.researchgate.net/publication/221344771_Qualitative_reverse_engineering
Terek, M. (2010). Hĺbková analýza údajov. Retrieved from https://www.portalvs.sk/sk/prehlad-projektov/kega/3027
Vogetseder, G. (2008). Functional analysis of real world truck fuel consumption data. Retrieved from http://www.diva-portal.org/smash/get/diva2:238366/FULLTEXT01.pdf
Vom Brocke, J. V., & Mendling, J. (Eds.) (2018). Business Process Management Cases. Digital Innovation and Business Transformation in Practice. Cham: Springer. http://dx.doi.org/10.1007/978-3-319-58307-5
Vukšić, V., Bach, V. B. M., & Popovič, A. (2013). Supporting performance management with business process management and business intelligence: A case analysis of integration and orchestration. International Journal of Information Management, 4(33), 613-619. https://doi.org/10.1016/j.ijinfomgt.2013.03.008
Waller, M. A., & Fawcett, S. E. (2013). Data science, predictive analytics and big data: A revolution that will transform supply chain design and management. Journal of Business Logistics, 34(2), 77-84. http://dx.doi.org/10.1111/jbl.12010
Wegener, D., & Rüping, S. (2010). On integrating data mining into business processes. Business information systems. Lecture Notes in Business Information Processing, 47, 183-194. http://dx.doi.org/10.1007/978-3-642-12814-1_16
Zhang Y., Zhang G., & Du. W. (2015) An optimization method for shopfloor material handling based on real-time and multi-source manufacturing data. International Journal of Production Economics, 165, 282-292. http://dx.doi.org/10.1016/j.ijpe.2014.12.029
Vehicle communication system Dynafleet Online – Volvo Truck Corporation
Integrating Business Process Management and Data mining for organizational decision-making
Abstrakt
Bezsporne jest, że ciągły rozwój technologii cyfrowych wpływa na otoczenie biznesowe. Korzystanie z technologii informatycznych oznacza łatwiejszy dostęp do ogromnej ilości informacji biznesowych, co trudno jest uwzględnić w codziennym podejmowaniu decyzji. Tradycyjne metody przetwarzania danych w zarządzaniu przedsiębiorstwem stają się nieodpowiednie. Podejście do zarządzania procesami biznesowymi i analiza danych biznesowych to narzędzia, które można wykorzystać do optymalizacji procesów w firmie i do zebrania cennych informacji, które mogą dostarczyć różnorodnych materiałów decyzyjnych do zarządzania firmą. Artykuł dotyczy analizy, modelowania i optymalizacji procesu transportu, a także projektowania systemu wspomagania decyzji w tym procesie w małej firmie transportowej. Badania koncentrują się na opracowaniu innowacyjnego systemu wspomagania decyzji opartego na analizie danych firmy w celu usprawnienia zarządzania procesem transportu.
Słowa kluczowe: wsparcie decyzyjne, proces obsługi transportu, analiza danych, zarządzanie przedsiębiorstwem
Biographical notes
Ing. Miroslava Nyulásziová, Ph.D., assistant professor at the Technical University of Košice, Faculty of Economics, Department of Applied Mathematics and Business Informatics. Her scientific research focuses on data analysis and machine learning.
Ing. Dana Paľová, Ph.D., assistant professor at the Technical University of Košice, Faculty of Economics, Department of Applied Mathematics and Business Informatics. Her research interests are related to education technologies and machine learning, eLearning, business informatics, and innovation in enterprises.